主题
Java Map集合完全指南
一、核心知识点
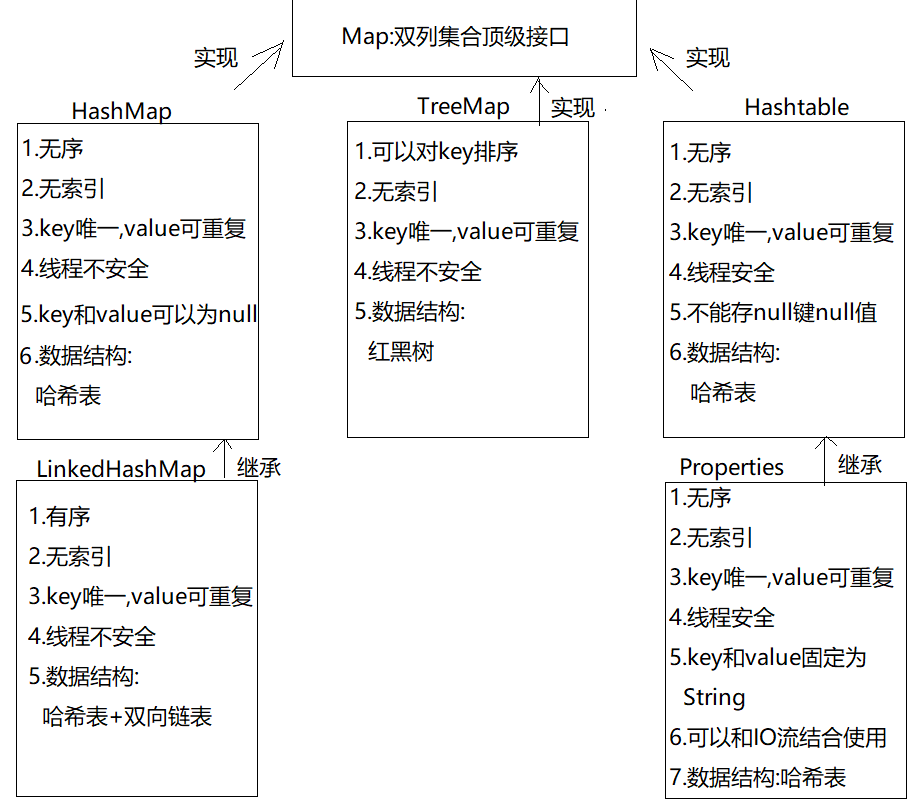
1. Map集合概述
1.1 基本概念
- 定义:双列集合的顶级接口
- 特点:一个元素由两部分构成(key和value,即键值对)
- 实现类:HashMap、LinkedHashMap、TreeMap、Hashtable、Properties
1.2 集合体系结构
2. HashMap详解
2.1 基本特点
- 无序:存取顺序不一致
- 无索引:不能通过索引访问元素
- key唯一:key不能重复,value可以重复
- 线程不安全:多线程环境下需要同步处理
- 可存储null:允许存储null键和null值
- 数据结构:哈希表(数组+链表+红黑树)
2.2 常用方法
| 方法 | 说明 |
|---|---|
V put(K key, V value) | 添加元素,返回被替换的value值 |
V remove(Object key) | 根据key删除键值对,返回被删除的value |
V get(Object key) | 根据key获取value |
boolean containsKey(Object key) | 判断集合中是否包含指定的key |
Collection<V> values() | 获取集合中所有的value,转存到Collection集合中 |
Set<K> keySet() | 将Map中的key获取出来,转存到Set集合中 |
Set<Map.Entry<K,V>> entrySet() | 获取Map集合中的键值对,转存到Set集合中 |
2.3 代码示例
java
@Test
public void test01() {
HashMap<String, String> map = new HashMap<>();
map.put("1","张三");
map.put("2","李四");
map.put("2", "王五");
map.put("3", "赵六");
map.put("4", "田七");
map.put("5", "朱八");
System.out.println(map);
String value = map.remove("1");
System.out.println("被删除的value: " + value);
System.out.println(map);
String value1 = map.get("2");
System.out.println("key为2的value: " + value1);
boolean b = map.containsKey("2");
System.out.println("是否包含key为2: " + b);
Collection<String> values = map.values();
System.out.println("所有的value: " + values);
}3. LinkedHashMap
3.1 基本特点
- 有序:存取顺序一致
- 无索引:不能通过索引访问元素
- key唯一:key不能重复,value可以重复
- 线程不安全:多线程环境下需要同步处理
- 数据结构:哈希表 + 双向链表
3.2 使用示例
java
@Test
public void test02() {
LinkedHashMap<String, String> map = new LinkedHashMap<>();
map.put("1","张三");
map.put("2","李四");
map.put("2", "王五");
map.put("5", "朱八");
map.put("4", "田七");
map.put("3", "赵六");
System.out.println(map);
}4. HashMap的两种遍历方式
4.1 方式一:通过keySet遍历
java
@Test
public void test03() {
HashMap<String, String> map = new HashMap<>();
map.put("大郎","金莲");
map.put("岩朔","王婆");
map.put("硕鑫","雨姐");
Set<String> set = map.keySet();
for (String key : set) {
String value = map.get(key);
System.out.println(key + "=" + value);
}
}4.2 方式二:通过entrySet遍历(推荐)

java
@Test
public void test04() {
HashMap<String, String> map = new HashMap<>();
map.put("大郎","金莲");
map.put("岩朔","王婆");
map.put("硕鑫","雨姐");
Set<Map.Entry<String, String>> set = map.entrySet();
for (Map.Entry<String, String> entry : set) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key + "=" + value);
}
}5. Map存储自定义对象保证key唯一
5.1 原理说明
- Set集合存储元素都是存到了Map集合的key的位置
- key需要重写hashCode和equals方法
- 去重复过程:
- 先比较key的哈希值
- 再比较key的内容
- 如果哈希值不一样,存
- 如果哈希值一样,内容不一样,存
- 如果哈希值一样,内容也一样,去重复(value覆盖)
5.2 代码示例
java
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Person {
private String name;
private Integer age;
}
@Test
public void test05() {
HashMap<Person, String> map = new HashMap<>();
map.put(new Person("涛哥", 18), "廊坊");
map.put(new Person("硕鑫", 20), "济南");
map.put(new Person("岩朔",22), "通辽");
map.put(new Person("彭思",16),"辽宁");
map.put(new Person("彭思",16),"北京");
System.out.println(map);
}6. TreeSet
6.1 基本特点
- 可排序:可以对元素进行排序
- 无索引:不能通过索引访问元素
- 元素唯一:元素不可重复
- 线程不安全:多线程环境下需要同步处理
- 数据结构:红黑树
6.2 构造方法
TreeSet():对元素进行自然排序(ASCII码值)TreeSet(Comparator<? super E> comparator):按照指定规则排序
6.3 使用示例
java
@Test
public void test01() {
TreeSet<String> set = new TreeSet<>();
set.add("b.曲项向天歌");
set.add("a.鹅鹅鹅");
set.add("d.红掌拨清波");
set.add("c.白毛浮绿水");
System.out.println(set);
}
@Test
public void test02() {
TreeSet<Person> set = new TreeSet<>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o1.getAge()-o2.getAge();
}
});
set.add(new Person("张三", 18));
set.add(new Person("李四", 15));
set.add(new Person("王五", 20));
System.out.println(set);
}7. TreeMap
7.1 基本特点
- 可排序:可以对key进行排序
- 无索引:不能通过索引访问元素
- key唯一:key不能重复,value可以重复
- 线程不安全:多线程环境下需要同步处理
- 数据结构:红黑树
7.2 构造方法
TreeMap():将key按照自然排序(ASCII码)TreeMap(Comparator<? super K> comparator):将key按照指定的顺序排序
7.3 使用示例
java
@Test
public void test01() {
TreeMap<String, String> map = new TreeMap<>();
map.put("b", "汗滴禾下土");
map.put("a", "锄禾日当午");
map.put("c", "谁知盘中餐");
map.put("d", "粒粒皆辛苦");
System.out.println(map);
}
@Test
public void test02() {
TreeMap<Person, String> map = new TreeMap<>(new Comparator<Person>() {
@Override
public int compare(Person o1, Person o2) {
return o2.getAge()-o1.getAge();
}
});
map.put(new Person("张三", 18), "杭州");
map.put(new Person("李四", 15), "上海");
map.put(new Person("王五", 20), "北京");
System.out.println(map);
}8. Hashtable(了解)
8.1 基本特点
- 无序:存取顺序不一致
- 无索引:不能通过索引访问元素
- key唯一:key不能重复,value可以重复
- 线程安全:多线程环境下安全
- 不能存null:不允许存储null键和null值
- 数据结构:哈希表
8.2 使用示例
java
@Test
public void test01() {
Hashtable<String, String> table = new Hashtable<>();
table.put("1", "张三");
table.put("2", "李四");
table.put("3", "王五");
System.out.println(table);
}9. Properties集合
9.1 基本特点
- 概述:Hashtable的子类
- 无序:存取顺序不一致
- 无索引:不能通过索引访问元素
- key唯一:key不能重复,value可以重复
- 线程安全:多线程环境下安全
- 固定类型:key和value固定为String
- 数据结构:哈希表
9.2 特有方法
| 方法 | 说明 |
|---|---|
setProperty(String key, String value) | 存键值对 |
String getProperty(String key) | 根据key获取value |
Set<String> stringPropertyNames() | 获取所有的key保存到set集合中 |
void load(InputStream inStream) | 将流中的数据加载到properties集合中 |
9.3 使用场景
用于解析配置文件(xxx.properties、xxx.xml、xxx.yml)
配置文件说明:
- 存放"硬数据"的文件(用户名、密码、地址等)
- 数据以key=value形式存储
- 一个键值对写完需要换行
- key和value都是字符串,不要加""
- 尽量不要写中文
9.4 代码示例
基本使用:
java
@Test
public void test01() {
Properties properties = new Properties();
properties.setProperty("username", "tom");
properties.setProperty("password", "123456");
Set<String> set = properties.stringPropertyNames();
for (String key : set) {
String value = properties.getProperty(key);
System.out.println(key + "=" + value);
}
}读取配置文件:
配置文件内容(pro.properties):
properties
username=root
password=1234代码实现:
java
@Test
public void test02() throws Exception {
Properties properties = new Properties();
InputStream in = Demo01Properties.class.getClassLoader().getResourceAsStream("pro.properties");
properties.load(in);
String username = properties.getProperty("username");
String password = properties.getProperty("password");
System.out.println(username + ":" + password);
}10. 集合嵌套
10.1 List嵌套List
java
@Test
public void listInList() {
ArrayList<String> list1 = new ArrayList<>();
list1.add("张三");
list1.add("李四");
ArrayList<String> list2 = new ArrayList<>();
list2.add("王五");
list2.add("赵六");
ArrayList<ArrayList<String>> list = new ArrayList<>();
list.add(list1);
list.add(list2);
for (ArrayList<String> arrayList : list) {
for (String s : arrayList) {
System.out.println(s);
}
}
}10.2 List嵌套Map
java
@Test
public void listInMap() {
HashMap<Integer, String> map1 = new HashMap<>();
map1.put(1, "张三");
map1.put(2, "李四");
HashMap<Integer, String> map2 = new HashMap<>();
map2.put(3, "王五");
map2.put(4, "赵六");
ArrayList<HashMap<Integer, String>> list = new ArrayList<>();
list.add(map1);
list.add(map2);
for (HashMap<Integer, String> map : list) {
Set<Map.Entry<Integer, String>> set = map.entrySet();
for (Map.Entry<Integer, String> entry : set) {
System.out.println(entry.getKey() + "=" + entry.getValue());
}
}
}二、重点难点
1. HashMap与Hashtable的区别 ⭐⭐⭐
| 对比项 | HashMap | Hashtable |
|---|---|---|
| 线程安全 | 线程不安全 | 线程安全 |
| null处理 | 可以存储null键null值 | 不能存储null键null值 |
| 效率 | 效率高 | 效率低 |
| 使用场景 | 单线程环境 | 多线程环境 |
相同点:
- 元素无序
- 无索引
- key唯一
- 数据结构都是哈希表
2. 各集合特点对比
List系列
- ArrayList:元素有序、有索引、元素可重复、线程不安全、数据结构为数组
- LinkedList:元素有序、无索引、元素可重复、线程不安全、数据结构为双向链表
- Vector:元素有序、有索引、元素可重复、线程安全、数据结构为数组
Set系列
- HashSet:元素无序、无索引、元素唯一、线程不安全、数据结构为哈希表
- LinkedHashSet:元素有序、无索引、元素唯一、线程不安全、数据结构为哈希表+双向链表
- TreeSet:对元素排序、无索引、元素唯一、线程不安全、数据结构为红黑树
Map系列
- HashMap:无序、无索引、key唯一、线程不安全、可存null、数据结构为哈希表
- LinkedHashMap:有序、无索引、key唯一、线程不安全、数据结构为哈希表+双向链表
- TreeMap:可对key排序、无索引、key唯一、线程不安全、数据结构为红黑树
- Hashtable:无序、无索引、key唯一、线程安全、不能存null、数据结构为哈希表
3. 哈希表存储元素细节 ⭐⭐⭐
存储流程:
- 先计算key的哈希值
- 再比较key的内容
- 如果哈希值不一样,直接存储
- 如果哈希值一样,内容不一样,存储
- 如果哈希值一样,内容也一样,去重复(value覆盖)
重要提示:
- 存储自定义对象作为key时,必须重写hashCode和equals方法
- Set集合保证元素唯一和Map集合保证key唯一的方式相同
三、常见面试题
1. HashMap的底层原理是什么?⭐⭐⭐
答案: HashMap的底层数据结构是哈希表,JDK 1.8之前是数组+链表,JDK 1.8之后是数组+链表+红黑树。
工作原理:
- 当调用put方法时,首先计算key的hash值
- 根据hash值确定数组中的位置
- 如果该位置没有元素,直接存储
- 如果该位置有元素(哈希冲突),遍历链表
- JDK 1.8优化:当链表长度超过8时,转换为红黑树,提高查询效率
2. HashMap和Hashtable的区别?⭐⭐⭐
答案:
| 对比项 | HashMap | Hashtable |
|---|---|---|
| 线程安全 | 线程不安全 | 线程安全(使用synchronized) |
| null处理 | 允许null键和null值 | 不允许null键和null值 |
| 效率 | 高(无同步开销) | 低(有同步开销) |
| 使用场景 | 单线程环境 | 多线程环境 |
| 推荐度 | 推荐 | 不推荐(使用ConcurrentHashMap替代) |
3. 如何保证HashMap的key唯一?⭐⭐
答案:
- 自定义类作为key时,必须重写hashCode()和equals()方法
- 先比较哈希值,再比较内容
- 如果哈希值不同,直接存储
- 如果哈希值相同但内容不同,存储
- 如果哈希值和内容都相同,覆盖value
4. HashMap的遍历方式有哪些?哪种效率更高?⭐⭐
答案:
方式一:通过keySet遍历
java
Set<K> keySet = map.keySet();
for (K key : keySet) {
V value = map.get(key);
}方式二:通过entrySet遍历(推荐)
java
Set<Map.Entry<K,V>> entrySet = map.entrySet();
for (Map.Entry<K,V> entry : entrySet) {
K key = entry.getKey();
V value = entry.getValue();
}效率对比:
- entrySet效率更高,因为只需要一次查询
- keySet需要两次查询:先获取key,再根据key获取value
5. TreeSet和TreeMap的排序方式有哪些?⭐⭐
答案:
自然排序:
- 元素类实现Comparable接口
- 重写compareTo方法
- 使用无参构造:
new TreeSet<>()
比较器排序:
- 创建Comparator实现类
- 重写compare方法
- 使用有参构造:
new TreeSet<>(comparator)
6. Properties集合的使用场景是什么?⭐
答案:
- 读取配置文件(.properties、.xml、.yml)
- 存储应用程序配置信息(数据库连接、系统参数等)
- 实现软编码,避免硬编码
- 方便修改配置,无需修改源代码
7. LinkedHashMap如何保证有序?⭐⭐
答案:
- LinkedHashMap继承自HashMap
- 在HashMap基础上维护了一个双向链表
- 记录元素的插入顺序或访问顺序
- 遍历时按照链表顺序输出
8. HashMap的扩容机制是什么?⭐⭐⭐
答案:
- 默认初始容量:16
- 默认负载因子:0.75
- 扩容阈值:容量 × 负载因子 = 16 × 0.75 = 12
- 当元素个数超过阈值时,扩容为原来的2倍
- 扩容后需要重新计算元素位置(rehash)
四、实用代码片段
1. 统计字符串中每个字符出现的次数
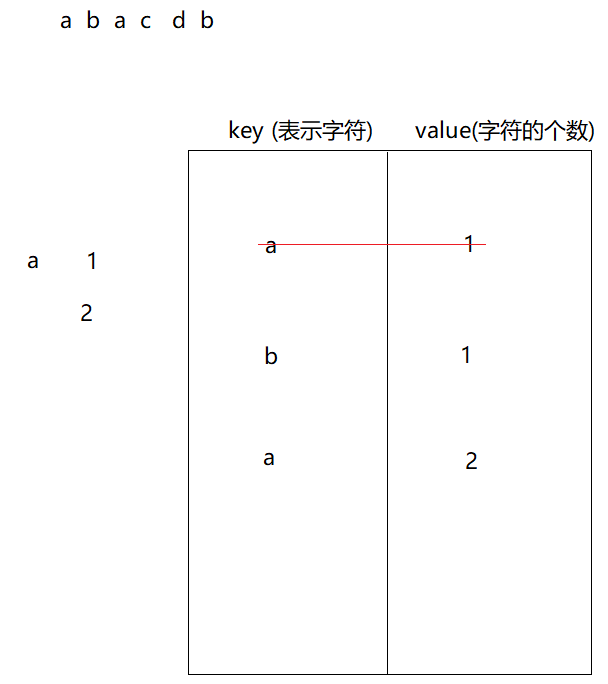
java
@Test
public void test06() {
String s = "adfasdfas";
HashMap<String, Integer> map = new HashMap<>();
char[] chars = s.toCharArray();
for (char c : chars) {
String key = c + "";
if (!map.containsKey(key)) {
map.put(key, 1);
} else {
Integer value = map.get(key);
value++;
map.put(key, value);
}
}
System.out.println(map);
}2. 使用Properties读取配置文件
java
public class ConfigReader {
private Properties properties = new Properties();
public void loadConfig(String fileName) throws IOException {
InputStream in = getClass().getClassLoader().getResourceAsStream(fileName);
properties.load(in);
}
public String getProperty(String key) {
return properties.getProperty(key);
}
}3. HashMap的线程安全处理
java
public class ThreadSafeMap<K, V> {
private final Map<K, V> map = new HashMap<>();
public synchronized void put(K key, V value) {
map.put(key, value);
}
public synchronized V get(K key) {
return map.get(key);
}
public synchronized V remove(K key) {
return map.remove(key);
}
}4. 使用TreeMap实现排序
java
@Test
public void sortedMap() {
TreeMap<Integer, String> map = new TreeMap<>(Collections.reverseOrder());
map.put(3, "C");
map.put(1, "A");
map.put(2, "B");
System.out.println(map);
}五、经典练习题
练习题1:Map集合统计字符出现次数
题目:用Map集合统计字符串中每一个字符出现的次数
要求:
- 指定一个字符串
- 创建一个map集合,key为String代表字符,value为Integer代表字符个数
- 遍历字符串,用每一个字符去判断,Map中是否包含字符
- 如果不包含,将字符和1存到map中
- 如果包含,根据字符将对应的value获取出来,让其+1,并重新存入
- 输出map
参考答案:见上文"实用代码片段"第1条
练习题2:List嵌套Map
题目:1班有三名同学,学号和姓名分别为:1=张三,2=李四,3=王五;2班有三名同学,学号和姓名分别为:1=黄晓明,2=杨颖,3=刘德华。请将同学的信息以键值对的形式存储到2个Map集合中,再将2个Map集合存储到List集合中。
参考答案:见上文"集合嵌套"第10.2节
练习题3:Map嵌套Map(作业)
题目:
- JavaSE集合存储的是学号键,值学生姓名
- 1(key) 张三(value)
- 2 李四
- JavaEE集合存储的是学号键,值学生姓名
- 1 王五
- 2 赵六
要求:
- 小map的key为学号,value为姓名
- 大map的key为字符串(javase,javaee),value为小map
提示:
java
HashMap<String, HashMap<Integer, String>> bigMap = new HashMap<>();六、扩展知识
1. HashMap在JDK 1.8的优化
主要优化:
- 引入红黑树:当链表长度超过8时,转换为红黑树
- 提高查询效率:从O(n)提升到O(log n)
- 减少哈希冲突的影响
2. ConcurrentHashMap(线程安全的HashMap)
特点:
- 线程安全
- 效率比Hashtable高
- JDK 1.8使用CAS + synchronized
- 推荐在多线程环境下使用
3. 集合选择原则
根据需求选择集合:
- 需要排序:TreeSet、TreeMap
- 需要有序:LinkedHashMap、LinkedHashSet
- 需要线程安全:Hashtable、Vector、ConcurrentHashMap
- 需要效率:HashMap、ArrayList
- 需要频繁增删:LinkedList
七、学习建议
1. 学习重点
- 掌握HashMap的底层原理和使用
- 理解哈希表的存储机制
- 掌握Map的两种遍历方式
- 理解TreeSet和TreeMap的排序机制
- 掌握Properties的使用场景
2. 面试准备
- 重点理解HashMap的底层原理
- 掌握HashMap和Hashtable的区别
- 理解哈希表存储元素的细节
- 掌握集合的选择原则
- 熟练编写Map的遍历代码
3. 实践建议
- 多写代码练习Map的使用
- 实现一个简单的HashMap
- 练习使用Properties读取配置文件
- 尝试解决实际业务问题
- 理解集合嵌套的应用场景
4. 常见错误
- 忘记重写hashCode和equals方法
- 使用可变对象作为key
- 在遍历时修改集合
- 忽略null值的处理
- 混淆HashMap和Hashtable的使用场景
八、知识图谱
Map集合
├── HashMap(哈希表)
│ ├── 无序、无索引、key唯一、线程不安全、可存null
│ ├── LinkedHashMap(哈希表+双向链表)
│ │ └── 有序、无索引、key唯一、线程不安全
│ └── 常用方法:put、get、remove、keySet、entrySet
├── TreeMap(红黑树)
│ ├── 可对key排序、无索引、key唯一、线程不安全
│ └── 排序方式:自然排序、比较器排序
├── Hashtable(哈希表)
│ ├── 无序、无索引、key唯一、线程安全、不能存null
│ └── Properties(属性集)
│ └── key和value固定为String,用于配置文件
└── 集合嵌套
├── List嵌套List
├── List嵌套Map
└── Map嵌套Map